본 논문은 nips 2022에 accept 된 논문이고, 현재 인용수는 1105회이다.
real data와 fake data의 에너지가 다르다는 인사이트를 얻기 위해 논문을 읽게 되었다.
Abstract & Introduction
본 논문에서는 out of distribution data를 탐지할 때 energy score를 사용할 수 있다는 것을 제시한다.
기존에 사용하였던 softmax score의 단점인 overconfidence를 줄일 수 있는 방법이라는 것을 제시한다.
OOD detection task: 학습이 완료된 모델이 새로운 샘플을 입력 받았을 때 ID 인지 OOD인지를 구분하는 태스크
- 학습할 때는 OOD detection이 아닌 이미지 분류 모델로 학습이 된다.
ID와 OOD data를 구분하는 energy surface를 만들어주는 energy function을 학습하는 것
energy fuction을 scoring fuction으로 사용한다는 것은 무슨 의미?
- 어떤 샘플을 scoring fuction에 넣으면 scalar 값을 내놓는다. 이 값을 통해 ID인지 OOD인지 구분한다.
- energy fuction을 거친 값에 따라서 ood인지 id인지 구분하겠다는 의미인것으로 이해했다.

위 그림에 따라서, negative energy score가 threshold 값보다 작으면 input을 OOD로 분류한다.
2. Background: Energy based model(EBM)
학습(Learning)을 energy의 관점에서 이야기해보면, 데이터를 바탕으로 어떤 energy surface를 만들어나가는데, 데이터가 있는 부분(공간)에 대해서는 낮은 energy를 할당하고(높은 확률) 다른 부분에는 높은 energy(낮은 확률)를 할당하는 과정이라고 생각할 수 있다.

즉 다음과 같은 그림을 목적으로 한다.
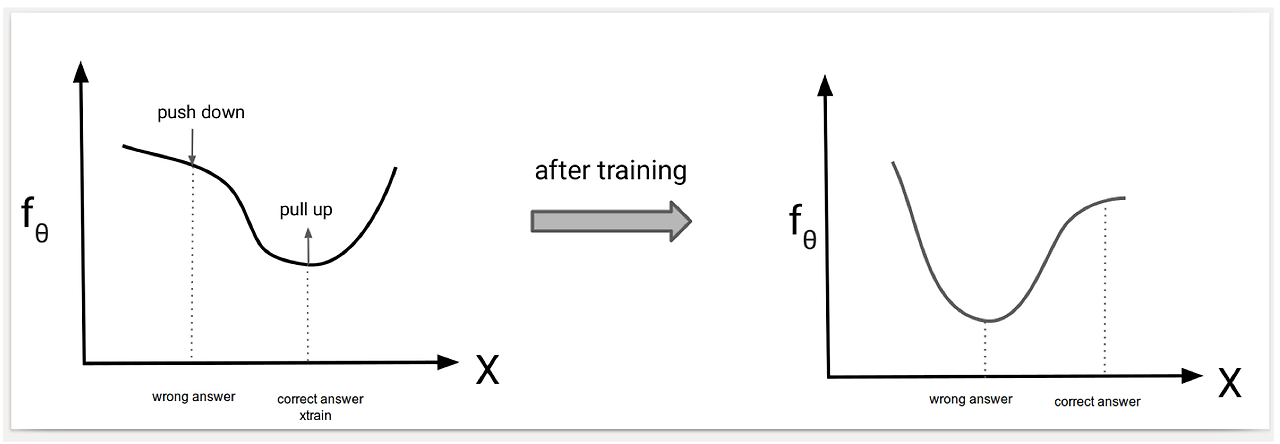
결국 Energy based model의 목적은 관찰한 training data에 대해서 energy를 최소화하고싶은 것이다.
이를 식으로 표현하면 다음과 같다.


EBM은 치명적인 단점을 가지고 있는데, normalizing constant Z를 계산하는 것이 어렵다는 점이다.
Z를 계산하기 위해서는 모든 데이터포인트에 대해 적분을 취해야하는데 이는 현실적으로 불가능한 일이다. 따라서 이를 최대한 피하는 방법을 통해서 EBM의 학습과 샘플링을 진행한다.
3. Energy- based out of distribution detection
우리는 id와 ood 간의 에너지 차이를 구분할 수 있는 energy score를 제시한다
3.1 Energy as inference-time ood score

앞서 normalizing constant Z를 계산하기 intractable하다고 이야기했었다.
이 문제를 완화하기 위한 key observation은, normalization이 없어도 OOD Detection에는 영향을 끼치지 않는다는 것이다.
일어날 확률이 높은 데이터 포인트는 낮은 에너지를 가진다.

위 식에서 알 수 있는 것은 log likelihood fuction이 -E(x; f) 와 lineary aligned되어있다는 것이다. 이것은 OOD detection을 하기에 이상적이다.
예를들어, 높은 에너지를 가지는 샘플은 낮은 likelihood를 가지고, OOD input으로 여겨진다.
다음처럼, 에너지가 특정 threshold를 넘으면 OOD로 그렇지 않으면 ID로 판별할 수 있도록 구성한다.
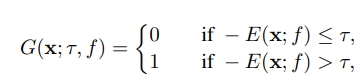
본 방법은 density Z를 추정하지 않아도 된다. x는 sample independent하고 전체적인 energy score 분포에 영향을 주지 않기 때문이다.
Energy score vs Softmax score
본 방법은 사전학습된 neural network에 대해 softmax confidence score를 간단히 대체할 수 있다.
여기 내용 이해를 못했다....

WideResNet으로 사전학습된 CIFAR-10 샘플의 softmax와 logit을 계산했다.
ood sample은 SVHN dataset으로부터 가지고 왔다.
(a)를 보면, ood sample과 id sample의 confidence는 거의 유사하다.
대조적으로, (b)를 보면 id sample과 ood sample의 energy score는 차이가 난다.
결과적으로, softmax confidence score는 id sample과 ood sample을 구분하지 못하지만, energy score는 두 샘플을 구분할 수 있는 유용한 정보를 담고 있다는 것을 알 수 있다.
3.2 Energy-bounded learning for OOD Detection
energy score가 사전학습된 neural network에 대해 id와 ood sample을 잘 구분해낸다고 해도, 항상 구분하기에 최적인것은 아니다. 따라서 본 논문에서는 energy-bounded learning objective를 제시한다. 이 방법은 neural network를 fine-tuning하여 id와 ood간의 명백한 에너지 차이를 만드는 것이다.
구체적으로, 우리의 energy-based classifer는 다음 목적함수를 통해 학습된다.

여기에서 F(x)는 classification model의 softmax output이다. 이 목적함수는 standard cross-entropy loss를 regularization loss와 결합한 것이다.

위 loss는 모델이 다음과 같은 역할을 하도록 한다.
specified margin m_in 보다 높은 에너지를 가지는 id sample에 패널티를 준다.
그리고 margin parameter m_out 보다 낮은 에너지를 가지는 ood sample에 패널티를 준다.
따라서 loss fuction은 m_in과 m_out 사이의 에너지를 가지는 샘플에 패널티를 준다.
모델이 fine-tuning되고 나면, downstream OOD detection은 3.1과 유사하다.
Experimental Results
4.1 Setup
In-distribution datasets: SVHN, CIFAR-10, CIFAR-100
Out-of-distribution datasets: Textures, SVHN, Places365, LSUN-Crop, LSUN-Resize, iSUN
CIFAR10과 CIFAR100에서 나타나는 예시들을 모두 제거했다.
Evalation metrics
평가지표에 대한 자세한 내용은 다음 포스트를 참고하기를 바란다.
https://mygreeeendiary.tistory.com/72
OOD Metrics(FPR95, AUROC, AUPR)
OOD Sample과 ID sample을 구분하는 OOD Detection task에서 자주 사용하는 Metric들에 대해 알아보자. 1) False Positive Rate(FPR95):모델이 높은 신뢰도로 ID 데이터를 식별하는 상황에서, 얼마나 많은 OOD 데이
mygreeeendiary.tistory.com
1) False Positive Rate(FPR95): 모델이 높은 신뢰도로 ID 데이터를 식별하는 상황에서, 얼마나 많은 OOD 데이터를 잘못 식별하는지 평가할 수 있다.
2) AUROC(the area under the receiver operating characteristic curve)
3) AUPR: the area under the precision-recall curve(AUPR)
Training Details
이미지 분류 모델을 학습하기 위해 WideResNet을 사용했다.
4.2 Results
Does energy-based OOD detection work better than the softmax-based approach?

에너지 스코어가 id 그리고 ood sample을 더 잘 구분할 수 있도록 해준다. 따라서 OOD Detection에 효과적이다.
How does out approach compare to competitive OOD detection methods?


How does temparature scaling affect the energy-based OOD detector?
How do the margin parameters affect the performance?
Does energy fine-tuning affects the classification accuracy of the neural networks?
참고링크
https://jaejunyoo.blogspot.com/2018/02/energy-based-generative-adversarial-nets-1.html
초짜 대학원생의 입장에서 이해하는 Energy-Based Generative Adversarial Networks (1)
Machine learning and research topics explained in beginner graduate's terms. 초짜 대학원생의 쉽게 풀어 설명하는 머신러닝
jaejunyoo.blogspot.com
https://process-mining.tistory.com/215
Energy-based model 설명 (EBM 설명)
Energy-based model은 데이터의 확률 분포를 energy function을 활용해 정의한 모델로, observed (혹은 more likely) data point에는 더 적은 에너지를, outlier (혹은 unlikely) data point에는 더 높은 에너지를 할당한다.
process-mining.tistory.com
01. Energy-Based Model
생성 모델의 확률 분포 $p_{\theta}(x)$는 두 가지 조건을 성립해야 합니다. * Non-Negativity: $p(x) \ge 0$ * Sum-to-One : $\…
wikidocs.net
'Study Log' 카테고리의 다른 글
| Out-of-distribution Metrics(FPR95, AUROC, AUPR) (0) | 2024.07.22 |
|---|---|
| Softmax 함수 출력의 의미 그리고 NLL loss (2) | 2024.07.22 |
| NeRF에 대하여 간단하게 정리 (0) | 2024.06.27 |
| Normalize flow 설명 | Flow-based deep generative models (0) | 2024.06.26 |
| PCA(Principal Component Analysis) 주성분 분석에 대하여 (0) | 2024.06.24 |



