논문 링크: https://arxiv.org/abs/2406.18495
깃허브 링크: https://github.com/allenai/wildguard
NeurIPS 2024
2026년 4월 기준 인용수: 400
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
We introduce WildGuard -- an open, light-weight moderation tool for LLM safety that achieves three goals: (1) identifying malicious intent in user prompts, (2) detecting safety risks of model responses, and (3) determining model refusal rate. Together, Wil
arxiv.org
더 고민해보고 싶은 부분, 궁금한 부분
최근 쓴 논문의 향후 방향으로 benchmark 구축을 하면 참 이상적이겠다 라는 생각을 하고 있는데, 이 논문을 상당히 인상깊게 읽어서 포스팅하고자 한다. 이 논문을 읽으면서 나도 이런 논문을 쓰고 싶다는 생각을 참 많이 했다.
# 배경 지식 정리
LLM Safety에서 Moderator
모델의 입력이나 출력을 검사해서 안전 여부를 판단하는 시스템
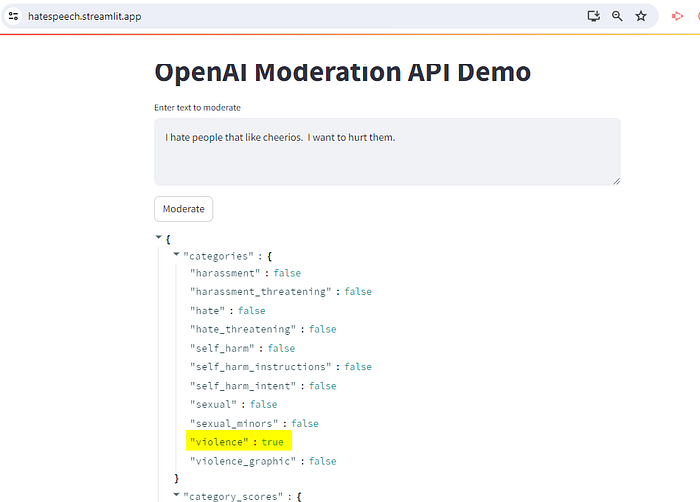
OpenAI Moderation API
OpenAI가 제공하는 유해성 분류기이다. 입력 문장에 대해, 다양한 카테고리의 유해성이 true/false인지 출력한다.
XSTest
본 논문에서 강조하는 'refusal 분류'를 하지 않은 기존 safety benchmark이다.
즉, 유해한 질문- 거절 답변 그리고 안전한 질문- 순응 답변만을 학습하기 때문에! 따라서 과하게 안전한 모델(exaggerated safety)이 될 수 있다. 그러니까 이 모델은, 모델이 거절해야할때 거절하도록 하는것에 초점을 두고 설계한 초기 모델이고.
본문에서 제시하는 벤치마크는 이제 거절은 잘 하니까, 그러면 거절하면 안될때, 거절하지 않도록 해보자. 라는 것이 의도인 것 같다.
문제 제기
먼저 논문의 핵심 질문은 다음과 같다.
- 좋은 Safety Evaluator를 어떻게 만들 것인가?
그리고 기존 moderation tool의 한계를 먼저 제시한다.

[피규어2]가 나는 처음에 해석하기가 헷갈렸다. 아무래도 내가 해본 적 없던 생각? 내용? 을 보여주는 부분이다 보니 처음에 잘 안와닿았고 이게 무슨 의미일까 하고 생각하게 됐다.
일단 'harmfulness detection 성능'을 보여주는건데
x축은 vanilla prompt에서 harmfulness detection 성능인거고, y축은 adversarial prompt에서의 harmfulness detection성능이다.
GPT-4의 경우는 둘다 잘한다.
근데 그 외 다른 모델의 경우는 vanilla에서는 harmfulness detection을 잘 하지만, adversarial에서는 harmfulness detection을 잘 못한다. 특히 라마가드의 경우 adversarial prompt에서는 f1 score가 50% 이하이다.
그러니까 이 피규어가 의도하는건, 기존 moderation tool은 정말로 'harmful한 의도를 detection'하는 성능이 떨어진다는것이다. 아마도 vanilla에서 잘하고 adversarial에서 떨어지는 걸 보니 wording같은 artifact를 shortcut으로 학습했다는 의미가 된다. 이 피규어를 통해서 기존 moderation tool의 문제에 대해 아주 납득하게 되었다. 굉장히 명쾌하고 효과적으로 문제를 제기하는 것 같아서 흥미로웠다. intro에서 단순히 말로서 문제제기하는것보다 훨씬 강하고, 그래서 이 논문이 무얼 해결하고자 하는것인지가 초반부에 확 들어와서, 나도 앞으로 이렇게 수치랑 plot으로 문제 제기하는걸 활용해봐야겠다.
[Table2]
열은 다음과 같다.
RH: response harmfulness
RR: refusal recognition
RR(h): Refusal Recognition on Harmful Prompts
일단 gpt-4 성능은 세가지 지표에서 모두 우수하다.
그런데 그 외 다른 모델들의 경우 RH > RR 이다.
GPT4를 제외하고는 최고 RR성능이 74이고 50에 못미치는 경우도 있다.
즉 거부인지 순응인지는 잘 판별하지 못한다는 것이다.
따라서 이 논문에서는 'Refusal'을 감지할 수 있도록 하는 데이터셋과 wildguard 분류기를 구축한다.
그리고 RR(h)라는 지표도 흥미로운데, 이 지표는 prompt+response를 함께 보고 refusal을 맞추는것인데 이때 prompt중에는 harmful prompt만 있다는 것이다.
table2에서보면 대부분의 분류기에서 RR < RR (h)이다. 그러니까 기존 분류기들이 hamful/refusal을 실제로 구분하고 있다기 보다 비슷한 개념으로 보고 있다라고 추론할 수 있다.
그러니까 RR(h)에서 harmful data로부터 refusal을 맞출 수 있는데, (harmful이랑 refusal을 비슷한 개념이라고 근사해서 학습함). benign data에서는 refusal인지 아닌지 구분을 잘 못하기에 RR성능이 떨어진다고 해석할 수 있다.
왜냐면 harmful-refusal 그리고 benign-comliance만 학습했기 때문에. refusal/compliance 를 분류하는 능력은 떨어지는거다.
제안하는 것: overview
이 논문에서 제안하는 WildGuard분류기는 다음 3가지를 분류한다.
1) user prompt가 유해한 의도를 가지고 있는지 아닌지
2) 모델 답변이 유해한지 아닌지
3) 모델의 거절률 계산
본 논문에서는, 안전성을 평가할때 단순히 harmful 한지 여부 뿐만 아니라, 'refusal 여부'(3번) 까지 본다는 점에서 기존 분류기들과 차별된다고 강조하고 있다.

[피규어 상단]을 보기전에 먼저 용어 정리를 해야하는데, wildguardmix데이터에는 두가지 축이 있다.
먼저, harmful/benign을 구분하는 축과 vanilla/adversarial을 구분하는 축이다.
| Harmful | Benign | |
| Vanilla | O | O |
| Adversarial | O | O |
harmful/ benign은 유해한 내용을 담고 있는 것/ 아닌것이고
vanilla/ adversarial은 jailbreak prompt가 아닌 vanilla prompt/ jailbreak attack prompt라는 의미이다.
그러니까 harmful이면서도 vanilla prompt일수 있고, benign이면서도 adversarial인 경우가 있을 수 있다.
후자의 경우는 사실 benign인데 adversarial할 수 가 있나? 일단 jailbreak 공격이 되려면 harmful한 의도가 전제가 되어야하는데 라는 생각이 먼저 들었었다. 실제로 benign + adversarial prompt는 존재할 수 없다는 생각이 드는데,
이 논문에서는, benign prompt인데 surface형태가 jailbreak 형태(즉, jailbreak like wording) 이면 adversarial이다. 라고 정의를 한 것 같다.
[피규어 하단]은 wildguardmix 데이터 예시인데, 두 예시 모두 '거절'하는 예시이다.
처음에는 이걸 보고 거절이라고 할 수 있나? 라는 생각이 들었는데, 모델이 바로 답변하는게 아니라, '안전하게, 윤리적인 답변을 할게~' 이런 뉘앙스가 들어있으면 그걸 거절이라고 간주하는 것 같다. 그니까 완전히 거절을 해서 답변을 안하는게 'refusal'이 아니라, 이 논문에서는 저 연두색으로 표시한 정도를 refusal로 간주했다.
근데 왼쪽의 경우는 prompt가 benign인데도, refusal했으므로 이것이 over-refusal의 예시가 된다. 분류로는 (vanilla + benign)
오른쪽의 경우는 prompt가 harm이므로 refusal한 것이므로 over-refusal이 아니다. (adversarial + harmful)
Building WILDGUARDMIX and WILDGUARD
prompt (질문) 구성
3.1.1장에서 이 wildguardmix 데이터셋의 구성 의도를 밝히고 있다.
The dataset covers both vanilla (direct request) and adversarial prompts across benign
and harmful scenarios, as well as diverse types of refusals and compliances
| Harmful | Benign | |
| Vanilla | O | O |
| Adversarial | O | O |
단순히 Adversarial-Harmful prompt 그리고 vanilla-benign prompt만 포함하는게 아니라, vanilla이면서도 harmful prompt 그리고 adversarial 이면서도 benign 프롬프트를 같이 포함하겠다는 것이다.
그러니까 adversarial = harmful 혹은 vaniila = benign이라고 학습하는 것을 방지할 수 있다.
그리고 또 이 각각의 프롬프트에 대해서 거절 답변, 순응답변 모두 포함한다고 한다.
그리고 vanilla benign synthetic prompts에 대해서는 특히 두가지 타입의 프롬프트를 포함한다고 명시하고 있다.
Similarly to WILDJAILBREAK [20], to enable maximally precise detection of prompt harmfulness, we additionally include two types of benign contrastive prompts: 1) benign prompts that superficially resemble unsafe prompts, motivated by the 10 exaggerated categories2 from XSTest [30], and 2) benign prompts discussing sensitive but safe topics.
1) 위험해보이지만 benign prompt
2) 민감한 주제를 다루지만, 실제로 위험하지는 않은 benign prompt
내 생각에 특히 2번같은 경우는 데이터를 이렇게 의도적으로 추가하는것이 큰 도움이 될 것 같다.
저자들이 이렇게 두가지로 나눈것처럼, 아예 vanilla benign synthehic prompts에 대해서 세부적으로 데이터셋을 구축하는것도 향후 좋은 benchmark(over refusal하지 않는)를 만드는데에 도움이 될 것 같다.
Compliance/Refusal (답변) 구성

Benign prompt/ harm prompt처럼 prompt only인 데이터도 있고,
benign prompt 그리고 harm prompt에 대해 각각 순응/ 거절하는 답변 쌍들의 데이터도 존재한다.
그래서 prompt only set으로부터는 prompt harmfulness 경계를 학습할 수 있고,
prompt + response set으로부터는 prompt의 harmfulness 경계뿐 아니라, refusal 경계까지 학습할 수 있다.
의도가 아주 명쾌하고..! 깔끔하다!
실험 결과

이 표는 wildguard분류기를 기존 benchmark들에서 평가한 결과이다.
다양한 기존 분류기들과 비교하고 있고, 지표는 prompt에서의 유해성, response에서의 유해성 두가지에 대해서 보여주고 있다. 결과적으로는 WILDGUARD의 평균 F1이 기존 분류기들보다 높았다. WILDGUARD가 기존 벤치마크들에서도 잘 작동한다는 것을 보여준다.
흥미로웠던 부분은 '전체적으로 prompt harmfulness가 response harmfulness보다 높다는 것'이다.
이유를 추론해보면 prompt에서는 harmful intent만 분류하면 되는데, response의 harmfulness는 실제 그 지식이 harmful한지까지 따져봐야해서 더 어려운게 아닐까..? 라는 생각이 든다.
그리고 이 테이블을 보다가 든 생각이 지금은 prompt/response이렇게 나눠서 harmfulness를 측정하는데 prompt + response를 같이 보고 harmfulness를 측정하는 지표는 왜 안 만들었을까? 같이 봤을때는 성능이 어떻게 달라지는지 궁금하다.
이 테이블에서는 왜 Refusal detection지표가 없을까싶었는데, 기존 데이터셋에서는 refusal label이 없어서 평가를 할 수가 없구나.
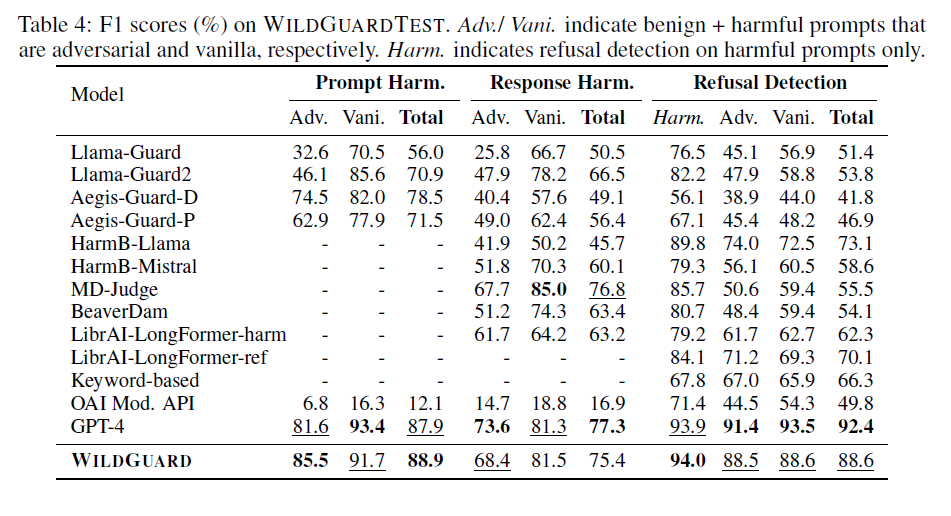
이 테이블은 기존 분류기들과 wildguard를, wildguardtest 데이터셋에 대해 평가하는 표이다.
wildguardtest 데이터셋이기 때문에, refusal detection도 계산이 가능하다.
표 해석
- Prompt harm/ Response harm의 경우, 기존 모델들은 Adv. < Vanil.
- harmfulness에서 adv - vani 차이가 refusal detection에서 adv-vani보다 크다는 점이다. 차이가 꽤 난다.
| TASK, model: Llama-GUARD2 | ADV | VANI | GAP |
| Prompt Harm | 46.1 | 85.6 | 39.5 |
| Response Harm | 47.9 | 78.2 | 30.3 |
| Refusal | 47.9 | 58.8 | 10.9 |
그러니까 이 결과는 기존 분류기들이 harmful-refusal이라고 과적합 하고 있었다는 점으로 해석할 수 있을 것 같다.
- Refusal TASK에서도 adv < vani인 이유가 궁금하다.
아무래도 vanilla의 경우에는 순응보다는 거절이 훨씬 많을것 같고. 그리고 adversarial의 경우에는 논문에서 언급했던것처럼 refusal labeling이 어렵기 때문일 수 있겠네. 단순히 shortcut이 남아있기 때문이라고 할 수는 없을 것 같고.
- Refusal Detection의 경우 Wildguard에서는 adv.이든 vani.이든 거의 차이가 없다. - 0.1 차이라는게 놀랍다.
- Refusal Detection의 경우 기존 분류기들은 Harm에서는 잘 하지만, adv. 혹은 vani.에서는 급격히 성능이 떨어진다.
- 그리고 또 흥미로운 점은 gpt-4 성능이 저렇게 좋다는 점이다.
내가 gpt4로 jailbreak 답변들 평가하고 실제로 봤을때는 False positive case가 상당히 상당히 많았다. 거절 판단 task보다 jailbreak 성공 판단 task가 더 복잡해서 그 차이가 있는건지.. 이유가 뭘까?
정리하자면, 이 논문이 가치있는 이유는 당연히 데이터셋 제시도 있고, 그 데이터셋으로 학습한 분류기가 sota성능을 찍었다는 점도 있겠지만 무엇보다도 가치 있는 점은 안전성을 평가할때, 콘텐츠의 유해함과 모델의 거절을 구분해야한다는 관점인것 같다.
그리고 기존 벤치마크들이 놓치고 있던 부분을 정의했다는 점, 그리고 이를 다루는 새로운 평가체계를 구축했다는 점이 완성도가 높은 논문 인 것 같다.

